Demystifying the magic of machine learning
Alex Kolchinski – June 2020
- Introduction
- The current wave of AI
- Background
- Areas of AI research and their applications
- The hype
- A few examples: real or hype?
- Artificial General Intelligence?
- Conclusion
Introduction
You’ve probably seen some pretty outrageous claims about what artificial intelligence (AI) can do. Maybe it’s been media headlines about how AI will soon be able to do everything humans can and will put us all out of work. Maybe it’s been company press releases about how their revolutionary AI technology will cure cancer or send rockets to the moon.
Those claims, and many others like them, are largely or entirely untrue, and are designed to draw attention rather than to reflect what is actually possible or likely to be possible soon. But AI really has made incredible advances in the last decade, and will continue to drive tremendous changes across our economy and society in the years to come.
Given that rapid progress, it’s important to be able to tell the outrageous claims about AI from those that are more credible, but how? Part of the reason I went to Stanford for grad school was to learn to do just that, and after doing quite a bit of AI research in different subfields, I’ve gained an intuition for what modern AI methods can really do. And by spending time in the world of startups, I’ve combined the more theoretical knowledge from the lab with a high-level understanding of how the advancements in research are being applied to the real world. I’ve found myself in many conversations with people wondering about exactly this question: which capabilities is AI quickly developing, and where will they be applicable? This is my attempt to distill those conversations into written form, and to spread a better understanding of the capabilities of AI in today’s world.
I’ve written this essay to be approachable by those without a background in computer science or statistics, but you’ll probably get the most out of it if you have a quantitative background. You’ll probably find it especially interesting if you’re in a STEM field and are wondering how AI is likely to change the way things are done in your world, or are in business and entrepreneurship and are wondering which opportunities AI is now opening up, and which older ways of doing things it’s threatening to make obsolete!
Update: Some readers have noted that this essay largely omits AI techniques other than deep learning. That’s true! Earlier waves of AI research are important both in a historical sense and because they’ve yielded many approaches that are still relevant to this day. Even after the advent of deep learning, many real-world problems are better solved by battle-tested techniques like logistic regression, decision trees, or any of a number of others. However, those techniques worked just as well ten years ago as they do today. The aim of this essay is to outline what is newly possible or becoming possible thanks to the current deep learning era of AI, and to draw a distinction between those real possibilities and problems that are either intractable or solvable without the need for deep learning techniques.
The current wave of AI
In the decades following the emergence of computers, the term AI has shifted meaning repeatedly. Over and over, computers have gained new capabilities – like winning at chess, or answering simple questions – thanks to the application of new techniques, or just greater availability of processing power. When those capabilities appear novel enough, they often generate a wave of excitement around AI, and the public conversation around AI becomes centered on those new capabilities, largely to the exclusion of previously novel but now-mundane techniques that had generated previous waves of excitement.
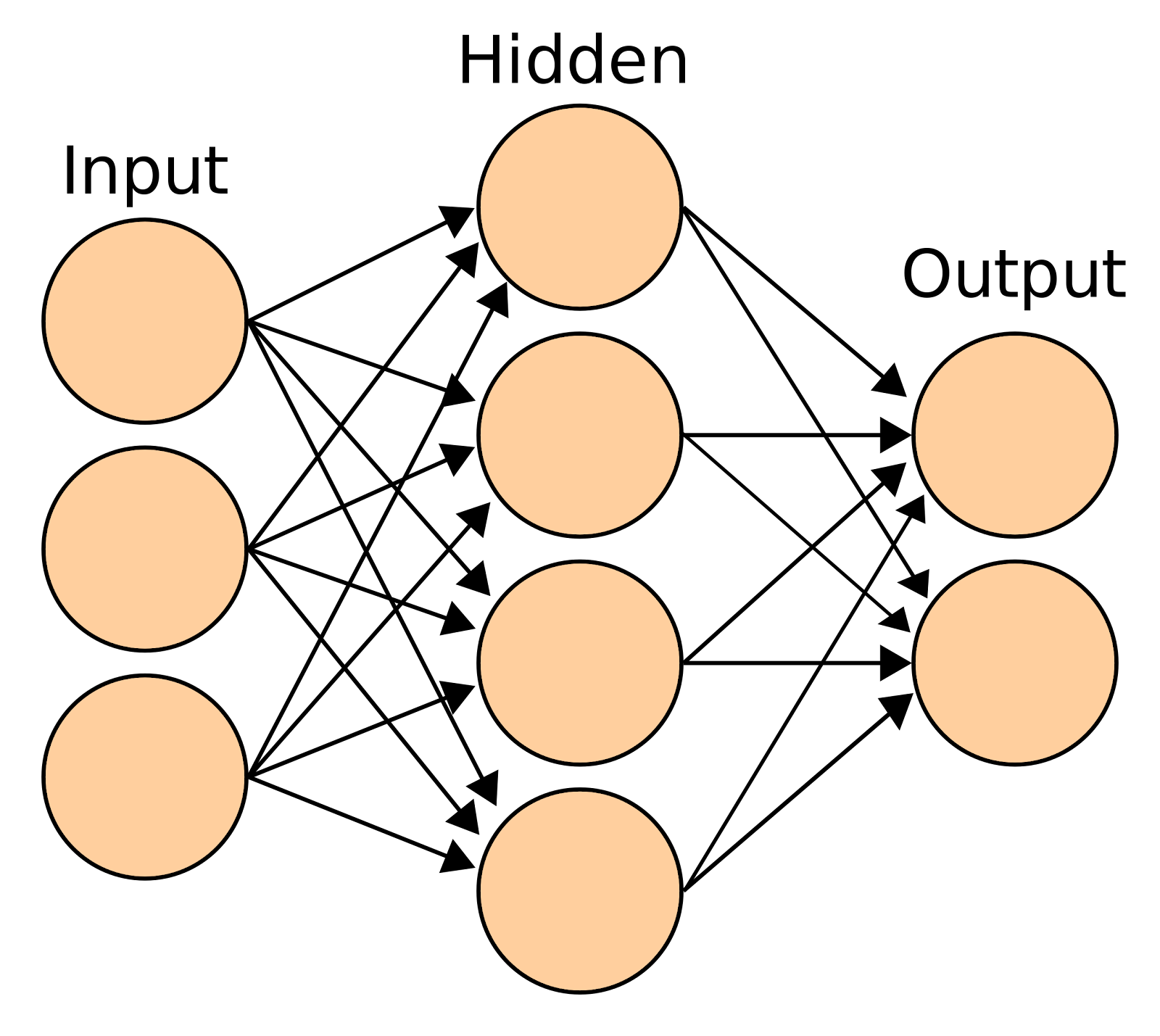
The current wave of excitement centers on a set of techniques known as deep learning, which have unlocked unprecedented performance in a wide range of real-world applications. Deep learning rests on a surprisingly simple technique: if you stack many very simple functions (a couple of examples in one dimension are y = 2x, or y = tanh(x)) one after the other, you can nudge, or train, the resulting many-layered function, or neural network, to map complex inputs to outputs with surprising accuracy over time. For example, if you want to tell pictures of cats apart from pictures of dogs, you might train your network to output 1s for dogs and 0s for cats. To conduct one step of training, you might input a photo of a dog into the network, and then if the output was incorrectly closer to 0 than to 1, nudge the layer functions of the network in a direction that will make the final output of the network slightly smaller. For example, this might mean nudging a function that is currently y=2x to be y=1.9x. With some tuning, repeating this process thousands or even millions of times is likely to yield a network that can tell cats from dogs with surprisingly high accuracy.
Of course, not all techniques currently referred to as AI are based on this deep learning approach, and the general excitement around AI has created plenty of nonsense — the joke goes that many startups tell the public that they’re an AI company, tell investors that they use machine learning, and internally use logistic regression (a simple and decades-old statistical technique) for some predictive task that may not even be core to their business model. A fictional example of this might be an online used-clothing marketplace, probably called something like mylooks.ai, that claims to be an AI company but in reality does nothing more than using simple statistics to predict when to send marketing emails to users to drive the most engagement.

But don’t be fooled by the hype: deep learning really has changed the game in terms of what AI can do in the real world. Computational techniques before deep learning were very good at working with structured data (tables, databases, etc.), but much less good at unstructured data (images, video, audio, text, etc.), which is often very important in the real world. Deep learning, unlike older approaches, is very good at dealing with unstructured data, and that is where its power lies. Tasks that were previously hard or impossible to do reliably, like image identification, have suddenly become almost trivial, unlocking many applications. This comic (https://xkcd.com/1425/), from less than a decade ago, is already out of date: identifying a bird in a photo is now straightforward!
All of these new abilities do come with a caveat: deep learning performance depends on huge amounts of data and computational power. The techniques of deep learning themselves have existed for decades, with limited applications like reading handwritten addresses for the postal service. But the limited availability of data and computational power hampered their performance until the 2010s, when two things happened. One was that the maturation of the Internet made vast amounts of text, images, and other unstructured data available. The other was the increasing performance of GPU chips, which were originally designed for gaming (I remember installing them in my gaming PC growing up!) but which, through a lucky accident, turned out to be incredibly useful for the acceleration of deep learning algorithms. When those two factors came together, deep learning made sudden and large gains in performance, which started drawing significant attention in 2012 when the AlexNet program smashed records on an image recognition challenge.
The resulting attention drew in huge numbers of researchers and engineers in both academia and industry, and there has since been incredible progress in both fundamental AI research and downstream applications. Unfortunately, the attention has also created tremendous amounts of unwarranted hype, especially in industry but even in academia. The stakes are high to be able to tell one from the other, whether you’re an engineer deciding whether to work at a company that claims to be developing commercially-relevant AI, a policymaker forecasting changes in employment numbers, or an entrepreneur trying to tell a real opportunity from a mirage.
So, what’s the best way to tell the real AI applications from the fake ones? The best strategy is to keep a finger on the pulse of what the research community is doing. With few exceptions, ideas that are deployed in industry are first published in the research literature, and then deployed (with modifications when needed) to a similar or analogous real-world task. Thus, an idea for an AI application that’s adjacent to something that’s already been published as a research finding is likely to be worth investigating, but one that’s totally unrelated to anything in the literature is best viewed with skepticism.
There are significant nuances to which ideas are truly adjacent to each other – telling cats from dogs is an extremely similar task to telling defective machine parts from functional ones, but classifying a sentence as happy or sad is much easier than classifying it as insightful or inane. However, gaining a broad familiarity with what the different research communities in the world of AI are working on is a great way to gain an intuition for what is truly possible or likely to soon be possible with AI, and that’s what the rest of this essay is about.
Background
Before we turn to a discussion of the communities in the world of AI research, it’s worth going over a few foundational ideas.
A term that’s closely associated with AI is machine learning (ML), which refers to AI approaches which learn from data, as opposed to being pre-programmed by humans. As most modern approaches to AI rely heavily or entirely on ML, the two terms have become synonymous in common usage.
An AI model is a configuration of functions which can be, or have been, trained on some task. For example, AlexNet is an image recognition model composed of many functional layers. You might train a previously untrained copy of AlexNet on millions of photos to classify them into categories, or you might use a copy of AlexNet that’s already been trained on millions of images to help you tell cats from dogs.
Deep learning techniques are applicable to a broad range of machine learning tasks, which can be roughly classified into many categories. A number of these, briefly described here, are commonly encountered, and worth knowing.
Reinforcement learning (RL) involves step-by-step decision-making by a model, e.g. the controls software for a robot which plays ping-pong. At every time step, an RL model has some information about the state of the world (e.g. the position of the paddle and the ball) and takes some action (e.g. moving the paddle to the right) based on its policy, which is the term used to denote the program that picks actions based on states. The policy is trained to maximize a reward signal, which is encountered intermittently (e.g. +1 reward for winning a point, -1 reward for losing).
Supervised learning is the setting in which a machine learning model is trained to map inputs to outputs. The model is trained with a labeled training set of known (input, output) pairs, and then tasked with predicting outputs corresponding to previously unseen inputs. Supervised learning can be further categorized into classification, where outputs are categories (“Is the animal in this photo a dog or a cat?”) and regression, where outputs are continuous (“How much does the dog in this photo weigh?”). Most current applications of deep learning in the real world fall under supervised learning.
Unsupervised learning is the setting in which there are no output labels in the training set, and the model’s task is instead to discover some structure in the input data. One common example of unsupervised learning is clustering, where the model is tasked with finding a grouping of the inputs (“Given these photos of animals, sort them into categories”).
One reason why the distinction between supervised and unsupervised learning is important is data efficiency. Hiring humans to label enough data to train a machine learning model in the supervised setting can easily cost thousands of dollars, and so a number of techniques exist to improve data efficiency and label efficiency, including:
- Semi-supervised learning: Only some inputs in the training set have labels.
- Weakly supervised learning: Some labels in the training set are incorrect.
- Transfer learning: Use a model trained on data from task A to get higher performance on related task B, without needing to gather more data from task B. Often, the same more-general “task A” is commonly used to train more-specific “task B”s, e.g. an ImageNet image classifier, trained on millions of photos to identify hundreds of common objects, being fine-tuned on just a few thousand new images to learn a more specific task like telling cats from dogs.
- Self-supervised learning (now in vogue!): Learn the structure of a domain by training a model to learn a function where both the inputs and outputs are available from unlabeled training data, e.g. predicting missing words in a paragraph of text, using the other words as input, or predicting missing pixels in an image, using the other pixels as input. The resulting model can then be used for transfer learning, e.g. training a model on arbitrary photos in the self-supervised manner, then fine-tuning on relatively few cat and dog photos to tell them apart from each other. This is a very useful technique as in many domains, unlabeled data is plentifully available from sources like Wikipedia and YouTube.
Labels aside, the availability of the training data itself is the most important factor in the performance of deep learning on tasks which are amenable to it. For example, even if you know that deep learning techniques are great at telling images of objects apart from each other, and want to train a model to tell Martian rocks from Earth rocks, deep learning won’t do you any good unless you have a lot of photos of both! In academia, research into new deep learning methods is largely conducted on publicly available datasets, a constantly evolving set of which is in broad use by the community. Achieving state-of-the-art performance on one of those commonly used data sets is a sought-after achievement in academic research. In industry, on the other hand, ownership of a hard-to-gather dataset can be a key competitive advantage for a company whose technology is powered by AI, as the most effective deep learning algorithms are largely public knowledge but the right data to train them for a specific commercially valuable task can be very hard to source.
The other key factor that dictates the performance of deep learning is the availability of computational power, often referred to as “compute” for short. Given a large enough training set of data, throwing more compute at the training process for a model will typically improve performance substantially. Indeed, achieving state-of-the-art (SOTA) results in some domains now costs hundreds of thousands of dollars in compute bills alone, and those numbers are only growing with time. A dynamic that this sometimes creates is that labs in industry, with their big budgets, will train huge models at great cost to achieve a SOTA result. Meanwhile, academic labs, with their more-modest resources, spend more of their effort on coming up with novel techniques that can drive higher and sometimes SOTA performance with less compute. A happy consequence of this second strain of research is that while achieving SOTA results keeps taking more and more compute and money, achieving the same level of performance on just about any task takes less and less compute with every passing year as the algorithms become more efficient.
Areas of AI research and their applications
Now that we’ve covered the broad categories and principles of machine learning, it’s time to dive into the most prominent areas of AI research. Application areas and types of machine learning intermingle freely: for example, ML for robotics may include both supervised learning for image recognition and reinforcement learning for controlling the robot.
In practice, deep learning has unlocked huge gains in performance in some very specific areas, and knowing what these are is very useful for gauging which applications are likely to be fruitful. Something that is closely related to work in these areas is likely to be achievable with a bit of research and development (R&D), while something totally unconnected is much more of a long shot in the near term.
Computer vision
Computer vision (CV) is the subfield of AI that deals with images, videos, and other related types of data like medical imaging. CV was the first field of AI to be revolutionized by the rise of deep learning, and it remains an extremely active area of research and applications. CV is also the most mature area of deep learning applications, and its high performance is well-understood and applicable to a number of tasks.

Deep learning has been so successful in CV applications for a number of reasons. One is that visual data is unstructured, and deep learning is much better at handling unstructured data than earlier approaches. In addition, deep learning – with its hunger for data – has thrived thanks to the newfound plentitude of visual data. From images on Google Images to videos on YouTube, the Internet is now full of visual content sourced mostly from now-ubiquitous smartphones.
Thanks to these factors, CV techniques powered by deep learning have been getting better and better at dealing with visual data. This is extremely important for downstream applications because visual data is able to capture a great deal of information about the physical world. Think of your own senses: while all are useful, sight is a particularly high-density way of gaining information about the world, from recognizing the objects around you to reading a book. Similarly, computers can now “see”, thanks to the advent of effective computer vision. This has unlocked all sorts of applications.
The most straightforward of those application areas is in tasks based on image classification, which consists of sorting pictures into categories, e.g. cats vs. dogs. The research into image classification has advanced so far that computers often exceed human performance. This has unlocked all sorts of downstream applications: given the right data, you can identify people’s faces to grant them access to a building, identify the items in a retail customer’s shopping basket to charge them automatically as they leave the store without the need for a checkout lane, or automatically identify defective parts in a factory.
Many more complex computer vision tasks exist as well. Two of common interest are object detection, which involves drawing a box around where certain objects are located in an image, and object segmentation, which involves precisely outlining the objects. Object detection has applications like identifying pedestrians in the field of view of an autonomous car’s camera(s). Object segmentation is useful for tasks like finding tumors in radiology images. If you want to locate objects in photos, that is now a very approachable problem.
Computer vision tasks are applicable to higher-dimensional data than 2D images as well. This includes things like 3D medical imaging and video. Video comes with its own set of challenges, including the need for huge amounts of compute due to the large number of frames. One common task in the world of CV for video is object tracking, or identifying where an object is from frame to frame of a video. This is useful in similar contexts as object detection in images, with the added capability of being able to handle movement; e.g. identifying a weed in the field of view of a weeding robot, so as to precisely spray it with herbicide.
Computer vision is rapidly gaining abilities on tasks which involve deeper inference as well. One of particular interest is pose estimation, where a CV model infers the positions of a person’s limbs and joints, or those of a robotic arm’s components, from a photo or video. This already works quite well and comes in handy for things like Snapchat filters, where being able to reliably identify the parts of someone’s face is important for then applying fun effects to it! Another intriguing research direction has been that of 3D reconstruction, or inferring the 3D shapes of objects from 2D images. There’s still plenty to be done there, but simpler “3D from 2D” inference for estimating sizes and distances to objects has been powering things like assisted braking in cars for over a decade.
What’s particularly interesting about computer vision is that it can enable the use of commodity cameras and software (the computer vision model) in places where previously, more customized hardware or human labor would have been required. For example, a factory might install a camera at entryways that only admits workers whose faces are recognized as authorized employees and who are wearing an approved helmet. In this way, a camera and software could replace both ID card scanners and helmet checks. Many more such use cases have already been developed, and many more will be in the years to come.
Computer vision can also serve as a surprisingly universal sensor for novel hardware, like enabling robots to “feel” objects by visually measuring deformation in the membrane that’s in contact with the object in question.
Of course, the fixed costs of training computer vision models for real-world tasks are usually quite high, due to the expense of both hiring researchers and engineers and collecting and labeling data (unless you are lucky enough to be able to use existing data like Wikipedia, but then your competitors will be too!) Deploying computer vision models, like deploying other machine learning models, also comes with the nontrivial variable costs of adjusting models to individual customers’ data and needs. These economics will dictate where computer vision is deployed in the next couple of decades, but expect to see it invisibly powering a wide range of applications across our economy in the decades to come.
Audio
The wide deployment of effective computer vision means that computers can now “The wide deployment of effective computer vision means that computers can now “see,” but they can also now “hear.” Just like visual data, audio data is complex and unstructured, which made it hard to work with before the rise of effective deep learning. And just like with visual data, deep learning has made it dramatically easier to work with audio – even more so than with visual data, as audio is simpler.
This has powered the rise of a number of applications. Ten years ago, speech-to-text transcription was painfully inaccurate; now, Siri and Google Assistant are able to transcribe spoken commands and questions with surprisingly high accuracy. Working with music has changed completely as well. Ten years ago, Pandora suggested music to users based on an extensive database of hand-tagged information about songs. Now, Spotify combines that approach with algorithms that actually analyze the songs themselves with the help of deep learning to better match them to users’ tastes.
Audio, while less studied in the research community than vision, is a very interesting field for AI applications because it’s the medium for human speech. Speech is in many ways the easiest and most natural way that we as humans communicate. That’s exactly why many tech companies are creating new platforms for audio interfaces, from Alexa speakers to Apple AirPods. Expect to see many more applications in the years to come, and to be interacting with computers more and more by talking to them. Numerous startups and big companies are working on the innovations to enable this change, and I expect many more to join them.
Natural language processing
Alongside computer vision, the natural language processing (NLP) community is one of the most active in the world of deep learning. Broadly speaking, natural-language processing has to do with any task that primarily deals with human language, like when Siri answers questions or Google Translate translates text from one language to another.
You may be wondering at this point why deep learning is applicable to natural language. After all, the types of unstructured data we’ve discussed so far are very different from language. Images, videos, and audio are all easy to represent in vector form – that is, as a long list of numbers. To simplify a bit, an image is a long list of pixel (dot) colors; a video is a long list of images, and an audio clip is a long list of sound intensities. But what about natural language? Each language is composed of some finite list of root words, and indeed, it’s possible to approach some NLP problems by assigning an integer index to each word and then training a relatively simple ML model not based on deep learning to solve the task, using the word indices as input data. This approach has worked well for some problems, like email spam filtering, but fails to capture the complexities that human language can express.
But it turns out that there’s a way to represent words as vectors that allows more complex machine learning techniques, including deep learning, to work well with natural language and blow the performance of techniques that work directly with indexed words out of the water. That way is known as word embeddings. The principle is relatively simple: each word in a human language has some rate at which it co-occurs with every other word in the language, where a co-occurrence is when the two words are used with fewer than 5 (or some other small number) words between them, indicating some association between their meanings. For example, “apple” and “tree” have a high co-occurrence frequency in English, while “apple” and “tangent” have a much lower one. In this manner, it’s possible to pick a set of reference words – e.g. the 10,000 most common words in English, and a reference set of text – e.g. Wikipedia, and for each English word found in Wikipedia, count up the number of times it occurs within 5 words of each of the 10,000 reference words. This yields a 10,000-dimensional vector (list of numbers) of co-occurrence counts for every English word found in Wikipedia. The resulting list of word vectors can then be reduced to fewer than 10,000 dimensions – 100 is a common choice – without too much loss of information, in a manner similar to drawing a cube on a flat piece of paper. This then leaves us with a ~100 dimensional word vector for most words in the language.
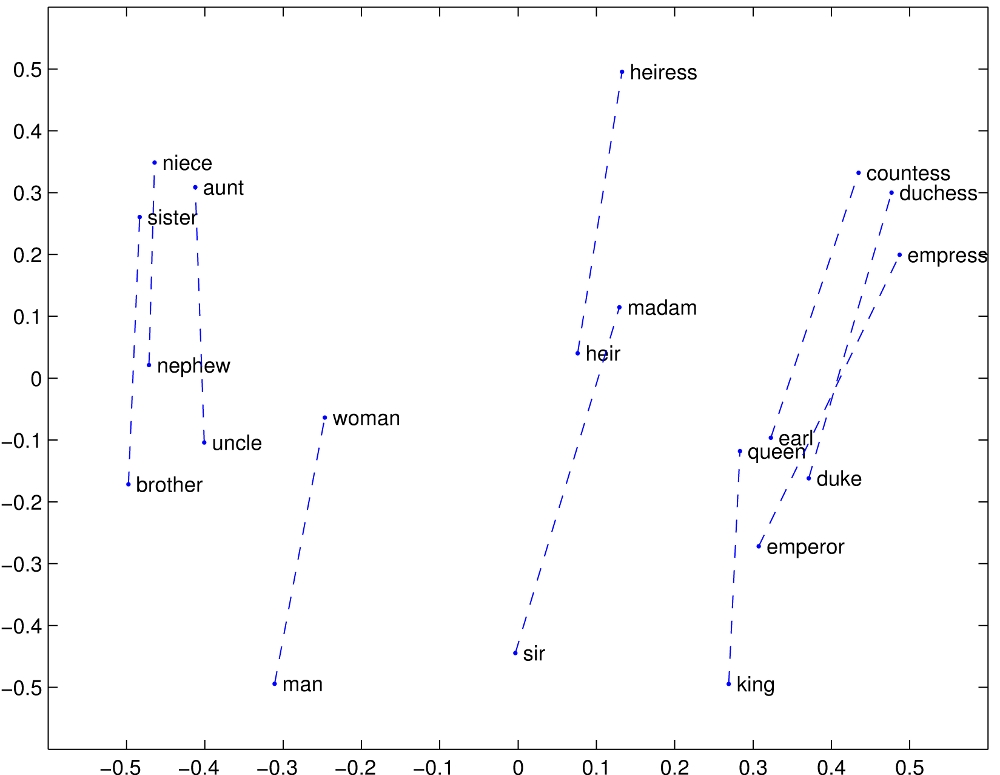
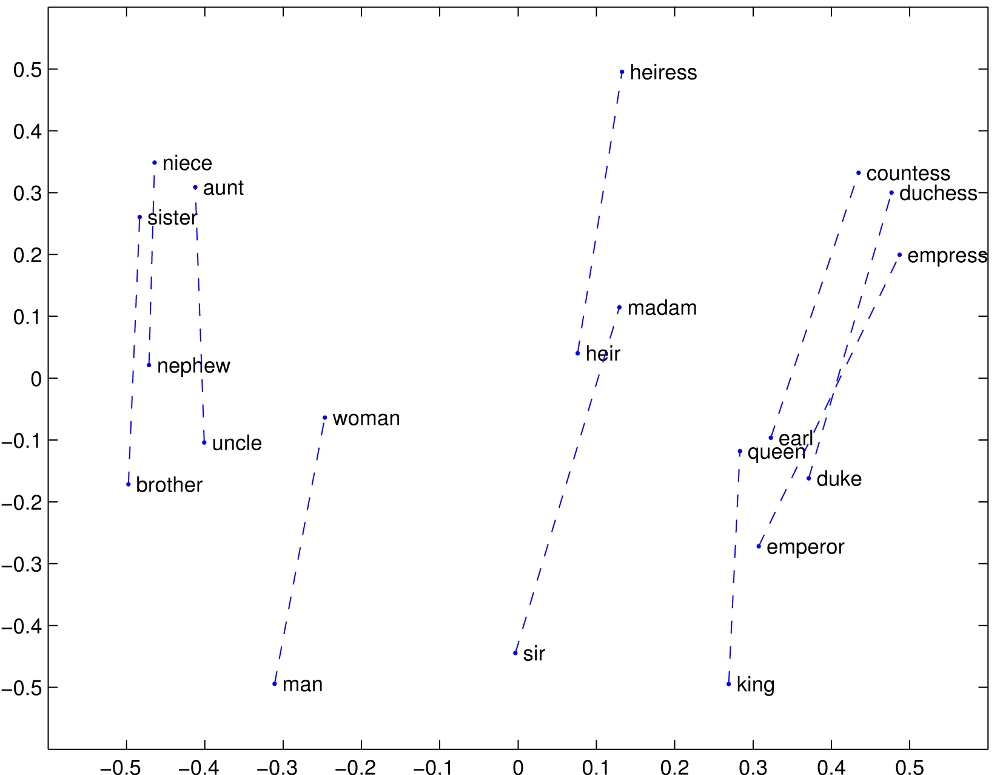
These word vectors, also known as embeddings, have some very interesting properties. For one, words with similar meanings tend to cluster together in the 100 (or 50, or 200…) dimensional space they are embedded in such that “apple” and “orange” are closer together than “apple” and “knight”. This is because “apple” and “orange” are often found near the same words, like “tree” and “eat”, while “knight” is more likely to be found near “chess” and “horse”. Remarkably, analogies are often preserved in the n-dimensional space in which the word vectors live. For example, “king” and “queen” are likely to be separated by approximately the same distance, in the same direction, as “man” and “woman”. Finally, and most remarkably, it turns out that the shapes of the “clouds” of different languages’ word vectors are similar enough between languages that it’s possible to line them up and figure out quite accurately which word in e.g. French corresponds to “dog”, or “horse”, in English – just by lining up the clouds of all the words in English and French. In this way, it’s possible to translate between languages with some degree of accuracy with no examples whatsoever of translations between the languages! In the 19th century, it was necessary to find the Rosetta Stone to start deciphering Ancient Egyptian, but in 2020 it’s possible to decipher a hitherto unknown language using nothing more than a large body of text in that language alone – thanks to word embeddings.
That said, word embeddings aren’t just useful in and of themselves; they also enable the application of deep learning to human language by mapping words to vectors, which deep learning techniques use as inputs. Ironically, in this case, mapping somewhat-structured data (individual words) to a less-structured but more numerical form (word vectors) enables higher performance on most NLP tasks.
The range of these tasks is quite wide. One important NLP task is translation. While it’s possible to translate between languages using word vector cloud alignment as described above, or using the older methods that powered Google Translate for years, modern techniques based on deep learning have achieved much better levels of performance. Many other tasks are constantly being worked on by the research community, including question answering, which involves finding the answer to a question in a body of text, and sarcasm detection, which is exactly what it sounds like. A good sampler of tasks currently of interest to the research community is found in the SuperGLUE benchmark, which is used to test the performance of NLP models. A broader list that gives a good overview of many NLP tasks is on this Wikipedia page.
The capabilities of NLP techniques have seen incredible progress over the past two years, more so than any other field of machine learning. Much of this has been driven by the rise of effective transfer learning for NLP. Just like a computer vision model trained on a large number of photos of objects to classify those objects into categories can then be trained on a smaller number of photos of e.g. cats and dogs to tell cats from dogs, an NLP model trained on a general task can be fine-tuned to a more specific task as well. The more general task is typically some variation of predicting missing words in a piece of text. The more specific task could question answering, sarcasm detection, or any of a number of others.
The trick is telling which tasks are well within the abilities of modern NLP, which tasks are on the horizon, and which are far in the future. Unfortunately, this is a difficult challenge, as human language itself is capable of expressing both very simple and very complex things.
Simpler NLP tasks which rely on surface-level language features are now generally approachable with a high degree of accuracy. For example, Grammarly has built a great business by making software that corrects word choice and sentence structure in a much more sophisticated way than traditional autocorrect – with technology powered by deep learning.
However, tasks which rely on some understanding of the meaning of text are more complicated. The most important thing to remember when it comes to those tasks is that state-of-the-art NLP models only capture patterns of words, not deeper meanings. So, a good model will “know” that “Eiffel” and “Tower” are closely related, and even that “baguette” is likely to follow in a subsequent sentence. But it will be unable to tell whether the narrator is 10km, 100km, or 1000km from Lyon unless it has been trained on text specifically mentioning the distance from Paris to Lyon, as it does not have any true knowledge of the world. There is now quite a bit of research effort to address this problem and imbue NLP models with more explicit knowledge about the world, but these efforts have not yet changed the game.
Despite this shortcoming, the state-of-the-art NLP models of 2020 are astonishingly powerful. The catch is that for complex tasks which require modeling the meaning of language, a model’s accuracy on that task will depend tremendously on the amount of specific data it is trained on. For example, a chatbot trained to answer common customer questions on a website might be able to achieve very high accuracy on a predefined and small set of interactions, if it is trained on something like 100,000 examples. But attempting to answer all customer questions would yield a much worse rate of appropriate responses, almost certainly low enough to be unacceptable for use by a business. For this and many other tasks, there is likely to be a “long tail” of examples that are especially hard for NLP models to handle. Leaving those to humans or some other fallback strategy while handling the more common examples automatically is a common strategy. This is what Amazon does with its customer support chat, when common queries are answered automatically but ones that the chatbot cannot answer confidently are routed to humans, and what Siri does by responding to only a small and fixed set of allowable questions and directing the rest to Google.
Those sorts of approaches, with a strategy of biting off common but simple NLP tasks that currently consume significant human effort, or are cost-prohibitive to do with human labor entirely, and automating them while leaving the more complex tasks to humans, are starting to gain steam and are poised to have dramatic impact in industry the years to come. There are many examples of successful use cases already. Gmail automatically suggests completions for sentences and canned replies to simple emails, but lets the user choose what to include in their message. Legal software lets lawyers and paralegals search through documents and identify notable clauses with much more power and precision than was possible with keyword-only search in the recent past. And reams of documents in fields like transportation and logistics are starting to be processed automatically for later reference by humans, thanks to the application of computer vision and NLP to document processing.
The recent advances made by NLP have both multiplied what it can do and reduced the difficulty of achieving high performance on many tasks. And the possible applications of these techniques are many. The channels that carry information between people are the sinews of the world economy, and people communicate in natural language, be that over the phone or electronic messaging. For the first time, we can work with that human-to-human information flow in scalable ways: reading an additional 100 articles about an industry per week used to mean hiring an additional analyst, and reading an additional 1000 used to mean hiring 10, but now, NLP summarization tools can summarize ten million articles almost as easily as they can summarize ten thousand.
Reinforcement Learning
Another extremely active area of research in the machine learning community, and one that has seen tremendous progress with the application of deep learning techniques, is the field of reinforcement learning (RL). Reinforcement learning is unlike other paradigms of machine learning in that it involves step-by-step decision making towards some goal. Some example tasks where an RL framework is relevant include playing video games and board games, and controlling robots and autonomous vehicles. In each case, there is a changeable state (e.g. the positions of pieces on a chessboard, or the pixels of an Atari game’s screen), possible actions that can be taken (legal moves in chess, or the steering input to an autonomous vehicle), and a “reward” that denotes a successful or unsuccessful outcome (e.g. a positive reward for winning a chess game, a negative reward for crashing a car) which is used as the signal to update the model.
The reward in RL is what frames the training process for the model. In the same way that a supervised learning model’s underlying functions are “nudged” when it makes mistakes on training examples to reduce similar mistakes in the future, an RL model’s underlying functions are “nudged” to be more likely to take actions that led to positive rewards, and less likely to take actions that led to negative rewards.

Reinforcement learning has seen tremendous advances in recent years thanks to the heavy application of deep learning techniques, with modern approaches (deep RL) able to defeat humans at the board game Go (previously the last stronghold of human superiority over computers in popular board games) and score highly at many video games.
However, as with other domains, the performance of deep learning techniques in RL is chiefly limited by the availability of data. And more so than in other domains, collecting data for training RL algorithms is fiendishly difficult, as the step-by-step nature of the setting often requires millions of iterations of alternatively applying the model to its target task and retraining it on the data gathered from those applications.
This means that in settings where running RL models and collecting data on their performance is cheap and fast – i.e. in settings that can exist entirely in a computer, like video games and board games – deep RL algorithms have shown tremendous gains in performance. But in settings where interaction with the real world is necessary for measuring the performance of models and collecting the data with which to improve their performance – like robotics and online education – the rate at which data can be collected is dramatically lower than in the fully virtual settings, and this has crippled the performance of deep RL in those settings. As a result, in settings like robotic control and autonomous vehicles, controls software is still not commonly powered by deep learning despite the power of those techniques in other areas.
There is now a significant push to close the gap between RL in virtual environments and RL in the real world, with one interesting direction being the use of simulation and its mapping to the real world, otherwise known as sim2real. For example, a deep RL algorithm for robotic control might be trained on a huge number of runs on a simulated robot, then fine-tuned on the real physical robot for thousands rather than millions of runs. These techniques show promise, but are still far from perfect. For example, OpenAI recently demonstrated a robotic hand that had been trained with a sim2real approach to solve a Rubik’s cube. Training the hand to work perfectly in simulation took them about 2 months, but getting it to then work in the real world took another 2 years, and the resulting performance was still extremely unreliable and only worked for configurations of the cube that required few moves to solve.
Another approach which is useful in addressing the data-inefficiency of reinforcement learning is known as imitation learning. Models trained by reinforcement learning typically blunder about for a long time after training starts, learning haphazardly to take actions that lead to positive rewards. Imitation learning instead trains models to choose actions that roughly imitate demonstrations of the task at hand, which are typically sourced from humans. One approach is to train a model with imitation learning on some number of human demonstrations (e.g. of people playing Tetris) and then to switch to trial-and-error reinforcement learning to further improve performance. This is apparently the approach taken by Pieter Abeel’s startup Covariant AI, which is attempting to train robot arms to move objects between bins in warehouses – a very hot area right now.
The bet that Covariant and its many competitors are placing is that while “RL for the real world” is not working well enough for most applications yet, it is on the cusp of a breakthrough that will unlock many new applications and billions of dollars of value. Indeed, RL is showing new and impressive results on a regular basis, from the abovementioned Rubik’s Cube robot hand to Google’s recent result showing success in designing layouts for computer chips (a very complex task) with the help of RL.
When the performance of RL crosses into industrially-useful territory, it is likely to follow a similar pattern as NLP technology: deployment in partnership with humans. Just as a chatbot might be able to handle 50% of customer inquiries automatically and route the rest to human agents, a bin-picking robot for warehouses might be able to handle 99% of objects and require humans walking around the warehouse to handle the 1% that are the hardest to pick up.
It is still unclear whether RL will cross the line into widely-useful performance in one year or in ten, but when it does, expect many consequences. Not the least will be much more adaptable robots, which will mean a number of use cases outside the factories and warehouses where most robots are currently deployed. Roombas may not be the only robots people encounter in their day-to-day lives for long!
Generative models

So far, we’ve discussed many ways in which deep learning models are able to process unstructured input data, whether it’s in the form of images, audio, video, text, or something else entirely. However, deep learning has enabled something else that’s quite remarkable: training models that output unstructured data.
What this means is that it’s now possible to train a model to generate new images, audio, text, etc. This can take the form of training a model on many images of people’s faces to generate new images of people who don’t exist at all. It can also take the form of training a model on Wikipedia articles to output plausible-seeming sentences and paragraphs. This works both in the non-conditional setting (“Given these millions of photos of people’s faces, come up with more that look similar”) and in the conditional setting (“Given these millions of paragraphs with accompanying audio clips of people reading them, learn to take a new paragraph and generate audio that sounds like someone reading it out loud”).
Just like NLP, generative models have seen tremendous advances in the last couple of years, and are now showing incredible results. It’s now possible to do things like generate extremely realistic images from nothing more than a text description or a sketch, or a video of a news anchor or politician giving a speech that they never gave at all (the controversial “deep fakes”), or to automatically generate captions for pictures and videos.

The potential for downstream applications are many. One area that’s already seeing substantial application of generative models is computational photography. It used to be the case that cell phone cameras were much less capable than full-fledged DSLRs with large lenses. But it turns out that in many cases, the software on the phone can more than correct for the shortcomings of the hardware. Deep learning like image denoising and image superresolution are able to dramatically increase the perceived quality of photos by inferring missing details, and companies like Google and Apple have already deployed these or similar techniques to their phones to enable things like professional-quality portraits and incredible low-light photography. One funny consequence may be the reliability of details in photos: for example, as more sophisticated algorithms are deployed to phones, a photo taken at dusk may look as good as one taken in the daytime, but the colors of objects may be slightly or even significantly wrong as the algorithm “guesses” those that there is not enough light to “see” properly.
Other artistic applications of generative models are sure to follow. Creative tools are likely to be some of the first areas to be disrupted. Imagine an alternative to PhotoShop where instead of having to manually airbrush out a pole and fill in the background, there was a button to “remove object” in one click that did it automatically. Or imagine an animation program that could automatically design a scene based on text instructions and place characters in it, then have those characters perform actions and express emotions based on high-level commands – removing the need to manually design much at all. Or a music production program that could automatically adjust the style of a song to be more exciting, or more menacing, or add incredibly realistic instruments to accompany a singer dynamically. These tools are likely to start out with much less room for customization and lower-quality output than existing high-effort tools, but enable hobbyists (even children and teenagers!) to produce songs and movies that would have previously taken much more skill and labor. This could have as much of an effect on the landscape of content production as the advent of the Internet and YouTube, SoundCloud, etc. Eventually, I expect the classic disruptive technology cycle to take place and the high-leverage creative tools to make their way upmarket and take over more and more of the creative software space.

Recommender systems
Recommender systems may well be the AI application that has already driven the most economic impact. Their purpose is to match content with users, whether that content is a video on YouTube, a movie on Netflix, or an ad on Google or Facebook.
Recommender systems are a key part of the “secret sauce” of a number of large companies, and often rely on proprietary data, so their development has mostly taken place in secret within the research labs of large companies, with little activity in academia. Thus, it’s hard for outsiders to tell just how capable they are, and what techniques are being used to advance the state of the art in the field. However, it’s safe to say from the incredible amounts of money made by Google, Facebook, Netflix and others that the systems work very well. It’s also a safe bet that deep learning has been having an impact on the field, whether by automatically analyzing the content of YouTube videos or even by enhancing the matching algorithms themselves.
Other optimization
Recommender systems are not the only “less sexy” under-the-radar place where modern AI can generate significant economic impact. Sophisticated quantitative finance firms like Renaissance and D. E. Shaw have likely been using deep learning to gain a competitive edge in the markets for much longer than those techniques have been in the public eye — likely since the 90s or even earlier.
But many other parts of the economy also rely on solving optimization problems to make money, from FedEx package routing to the operation of electrical grids. The optimization of these business problems, often referred to as operations research, has been the topic of study since at least the 1940s, and has met with great success. In many cases, well-established approaches from computer science and statistics, like linear programming, are more than adequate to find near-optimal solutions to business optimization problems.
But there are also cases where it will be possible to find better solutions to business optimization problems by finding complex patterns in high-dimensional data: exactly where deep learning excels. And even in cases where applying deep learning techniques can yield only a small edge over more traditional techniques, each percentage point of increased efficiency can be worth billions of dollars. As such, I expect that a number of companies are already hard at work in this space and that more will emerge in the years to come.
The hype
Alongside the places where deep learning-powered AI is truly driving huge progress, there are a number of realms where perception of the capabilities of AI far surpasses what it can actually do. Much of this is self-reinforcing: the more that everyone believes that AI is going to acquire incredible powers, the more they pay attention to it, and this creates incentives for the media to hype up the power of AI to draw clicks, and for businesspeople to hype up their usage of AI to draw media attention and investors dollars. Even AI researchers are often tempted to overstate the generality of their results to generate enthusiasm and win grants.
Interestingly, this cycle has played out a number of times before. Each time, a wave of progress in the genuine capabilities of AI excited public sentiment, which in turn incited a wave of overly enthusiastic promises from the media, business, and research communities. Eventually, expectations rose so high that after the technology inevitably failed to fulfil most of them, an “AI winter” followed, with enthusiasm and funding depressed for years.
I expect a similar dynamic to play out soon in public sentiment after AI fails to deliver most of the more outrageous things that have been promised over the past few years. However, I don’t expect a full “winter” to take place, as AI techniques are now creating incredible economic value as detailed in this essay, and that stream of money will continue to stimulate interest in AI in the business and research communities. Before long, we should reach a point where expectations of AI’s abilities are better matched to reality.
In the meantime, it’s best to treat the bolder claims around AI with a skeptical eye. Again, the best way to tell if a claim about a new AI application has a realistic chance of being true is to consider whether it lines up well with an existing research direction, or is similar enough that existing techniques that perform well are likely to generalize to it.
A few examples: real or hype?
Now, perhaps a few example claims are in order! Here, I’ll outline my opinions on a few that I’ve heard, either exactly or approximately, over the past couple of years. This list is of course far from exhaustive, but I hope it’s a useful sample of more and less realistic claims about what AI can do.
“We’re going to build an AI that can defeat humans at most video games.”: This one seems likely! RL techniques are well-suited to learning high performance on video games, and that performance is rising quickly. Of course, AI currently performs much better on some games than others, and there are likely to be games where humans have an edge for the foreseeable future.
“We’re going to build an AI that will be able to drive anywhere a human can.” This claim is one where reality has fallen far short of expectations. Training AI to interact with the physical world turns out to be a hard and messy problem, and driving human passengers is an area where mistakes are particularly costly. Expect to see autonomous driving roll out only in limited ways in the near future – e.g. small, slow food delivery vehicles which are unlikely to hurt anyone in a crash and can be remote-controlled in the case of unexpected circumstances (another example of AI deployment in partnership with humans!); Nuro is working on something like this. Highway trucking in good weather is another task that’s easier than full autonomy, and will have tremendous economic impact when even partially automated.
“We’re going to build an AI that will find drugs to cure diseases.” In theory, finding small molecules or biologics to bind to a known target to affect the course of a disease is a problem that can be solved computationally. In practice, computational approaches to drug discovery are at best an aid to wet-lab work. Could that change? Absolutely, but I haven’t yet heard of any applications of deep learning that are redefining performance in drug discovery in the same way that they did in image classification. Gathering data in this space is hard, simulations of binding affinity are far from perfect, and there is so much known structure in the domain – the laws of physics and chemistry – that deep learning, which is particularly good at discovering hard-to-find structure in data, may not be the right tool for the job. Computational modeling of drug candidates will improve, possibly with some help from deep learning techniques, but it is unlikely to replace in vitro and in vivo testing entirely due to the complexity of biological systems. This will change only when we can simulate a human body down to the molecular level, something unlikely to happen for many decades.
Update: Jonas Köhler has contributed a thoughtful post on Reddit disagreeing with some of my arguments here; I highly recommend taking a look!
“We’re going to build an AI that will teach students.” This one sounds great, and my hope of making progress in this direction is what led me to start a PhD at Stanford. However, it turns out that education is an incredibly complex and social task, and one that it is tightly coupled with just about everything that makes us human. We as humans have evolved to be able to infer each other’s thoughts and feelings in ways that let us teach each other effectively as well. This, however, is far from the capabilities of AI right now: if even realistic chatbots are out of reach right now, what hope is there for an electronic Socrates? There is educational software now that is reaching millions of learners (think Duolingo and Anki), and adaptive algorithms do contribute to its performance. However, I haven’t seen any cases so far where deep learning techniques outperform simple adaptive strategies like moving students to a new topic after they get three questions in a row right on the previous one. It may be that with more and more students interacting with educational software, the vast volume of data will yield significantly improved algorithms, but that’s going to be a tough nut to crack at best.
Artificial General Intelligence?

Finally, I would be remiss if I didn’t mention the debate around artificial general intelligence (AGI), also known as strong AI. AGI is essentially AI that can do everything a human can – and probably much more. Every time the state of AI advances, there tends to be alarm about the impending rise of AGI, like the famous example in the Terminator movies when the Skynet AI gains general intelligence and takes over the world. But in reality, we are almost certainly far from the advent of AGI. Human intelligence is still poorly understood, and so simulating it in a computer is not something that’s approachable directly.
It’s true that individual functions of the human brain, like visual and auditory perception, are now well-approximated by deep learning methods. But other faculties, like abstract reasoning, are still all-but-unapproachable by any ML techniques. Could this change, just as vision went from being unapproachable to almost trivial? Certainly, but that would require at least one and probably a number of breakthroughs in ML. And even if we learn to approximate all the functions of the human brain individually with ML, it will be some time before we stitch those programs together into a coherent whole and learn to train that model in a way that will teach it as much about the world as humans learn over a lifespan of decades. If AGI is gradually cobbled together from different advances in ML as it is now practiced, we will have plenty of warning, and the emergence is likely to be gradual enough that there is no single identifiable “before” and “after.”
It’s also possible to sidestep the complexities of duplicating the functions of human cognition one-by-one with ML and try to directly simulate a human brain neuron-by-neuron, but this too is a daunting problem. A brain is an incredibly complex system, not yet fully understood, and researchers have thus far been unable to simulate the nervous system of any creature more complex than a worm. There will surely be progress here as well, but here too it will be incremental. If there comes a day years or more likely decades from now when we build a supercomputer that successfully embodies a conscious human mind by simulating its physical structure, we will have hints that such a thing is in the works well before it actually happens, just like we would if existing approaches to ML gradually add up to full AGI.
Could we stumble into AGI in some way that doesn’t require decades of progress? The only way I can imagine this happening is if current deep learning methods turn out to be far more powerful than imagined. This isn’t entirely impossible: current methods have shown a remarkable ability to gain performance in areas like NLP from nothing more than constant increases in model size and computational power and data available for training the model. The company OpenAI claims to be pursuing exactly this strategy, apparently with a focus on reinforcement learning and similar approaches – the idea seems to be to expose increasingly huge RL models to increasingly complex real-world problems and see if AGI emerges.
However, it seems unlikely that these constant increases in power applied to existing techniques will yield a sudden breakthrough in performance that unlocks AGI. RL algorithms are so far incapable of so much as reliably solving a physical Rubik’s Cube. There seems to be no reason to believe that they will suddenly learn to do everything humans can. It is of course possible that this happens, and with that eventuality in mind it’s worth thinking through how best to manage the rise of AGI when it comes about – it will indeed be an incredibly powerful technology, maybe the most powerful ever in human history. But the day it comes into being is probably still decades away, if not longer.
Conclusion
In this time of quick progress in the capabilities of AI, it’s especially important to be judicious in telling new capabilities of the technology – and the opportunities they open up – with marketing hype, designed more to attract attention than to represent reality. Don’t be fooled by overly optimistic narratives, but also don’t assume that AI is all snake oil: there are many frontiers opening up ahead of us. For my fellow researchers and businesspeople reading this who will be opening those frontiers in the future, I wish you luck!
If you have any comments, please leave them below! I also welcome any messages at (My first name) @ (My last name).com – get in touch if you want to chat about AI, startups, or anything else that’s on your mind.
Further reading
There are vast quantities of writing on AI on the Internet today, but only some of it is of high quality. If you’re looking for more places to read about a high-level view of AI, I recommend reading around the Andereesen Horowitz site and blog, Benedict Evans’s newsletter, and Andrej Karpathy’s blog.
Acknowledgements
Many thanks to Anthony Buzzanco, Allie Cavallaro, Alex Gruebele and Anna Kolchinski for reading and editing drafts of this essay. This would have been far less readable without their help!

{kind=link}
{kind=link}
Leave a comment